Gem Series ++ Web Services (HTTP JSON APIs) the Modern Micro Way (Book Edition)
by Gerald Bauer, et al
- 1. almost-sinatra - Build Your Own (Micro) Webframework From Scratch with Rack and Tilt in Less Than Ten Lines
- 2. webservice - Script (Micro) Web Services (HTTP JSON APIs); Load (Micro) Web Services At-Runtime and More
- 3. worlddb - (Micro) Web Services (HTTP JSON APIs) Case Study - Seven Continents and the Countries of the World
- 4. beerdb - (Micro) Web Services (HTTP JSON APIs) Case Study - Cheers, Prost, Kampai, Na zdravi, Salute, 乾杯, Skål, Egészségedre!
- 5. sportdb - (Micro) Web Services (HTTP JSON APIs) Case Study - The World's Biggest Event - Russia 2018 - Football World Cup
- 6. feedparser - Meet Jason Feed - The Universal Content (Micro) Web Service (HTTP JSON API) - The Future of Publishing 'n' Online News
- 7. json-next - Comments, Please! - JSON 1.0, JSON 1.1, JSON What's Next?
- 8. feedtxt - TXT is the new JSON Case Study - Feeds in Text (Unicode) - Publish 'n' Share Posts, Articles, Podcasts, 'n' More
1. almost-sinatra - Build Your Own (Micro) Webframework From Scratch with Rack and Tilt in Less Than Ten Lines
Six lines of almost sinatra “unobfuscated” and bundled up for easy (re)use
github: rubylibs/almost-sinatra, rubygems: almost-sinatra, rdoc: almost-sinatra ++ more: comments on reddit, please!
What’s Sinatra?
Simple (yet powerful and flexible) micro webframework.
require 'sinatra'
get '/' do
'Hallo Vienna! Servus Wien!'
end
Trivia Quiz - Q: How Many Lines of Ruby Code?
- [A] 20 Lines
- [B] 200 Lines
- [C] 2 000 Lines
- [D] 20 000 Lines
What’s Almost Sinatra?
Sinatra refactored, only six lines now.
Library dependencies: Tilt and Rack (like Sinatra).
A hack by Konstantin Haase.
%w.rack tilt backports date INT TERM..map{|l|trap(l){$r.stop}rescue require l};$u=Date;$z=($u.new.year + 145).abs;puts "== Almost Sinatra/No Version has taken the stage on #$z for development with backup from Webrick"
$n=Sinatra=Module.new{a,D,S,q=Rack::Builder.new,Object.method(:define_method),/@@ *([^\n]+)\n(((?!@@)[^\n]*\n)*)/m
%w[get post put delete].map{|m|D.(m){|u,&b|a.map(u){run->(e){[200,{"Content-Type"=>"text/html"},[a.instance_eval(&b)]]}}}}
Tilt.default_mapping.lazy_map.map{|k,v|D.(k){|n,*o|$t||=(h=$u._jisx0301("hash, please");File.read(caller[0][/^[^:]+/]).scan(S){|a,b|h[a]=b};h);Kernel.const_get(v[0][0]).new(*o){n=="#{n}"?n:$t[n.to_s]}.render(a,o[0].try(:[],:locals)||{})}}
%w[set enable disable configure helpers use register].map{|m|D.(m){|*_,&b|b.try :[]}};END{Rack::Handler.get("webrick").run(a,Port:$z){|s|$r=s}}
%w[params session].map{|m|D.(m){q.send m}};a.use Rack::Session::Cookie;a.use Rack::Lock;D.(:before){|&b|a.use Rack::Config,&b};before{|e|q=Rack::Request.new e;q.params.dup.map{|k,v|params[k.to_sym]=v}}}
(Source: almost_sinatra.rb)
Almost Sinatra - A Breakdown Line by Line
Line 1
%w.rack tilt date INT TERM..map{|l|trap(l){$r.stop}rescue require l};$u=Date;$z=($u.new.year + 145).abs;puts "== Almost Sinatra/No Version has taken the stage on #$z for development with backup from Webrick"
Breakdown:
require 'rack'
require 'tilt'
trap( 'INT' ) { $server.stop } # rename $r to $server
trap( 'TERM' ) { $server.stop }
$port = 4567 # rename $z to $port
puts "== Almost Sinatra has taken the stage on #{$port} for development with backup from Webrick"
Aside - What’s rack?
Lets you mix ‘n’ match servers and apps.
Lets you stack apps inside apps inside apps inside apps inside apps.
Good News: A Sinatra app is a Rack app.
Learn more about Rack @ rack.github.io.
Aside - What’s tilt?
Tilt offers a standard “generic” interface for template engines.
Let’s check-up what formats and template engines tilt includes out-of-the-box:
require 'tilt'
Tilt.mappings.each do |ext, engines|
puts "#{ext.ljust(12)} : #{engines.inspect}"
end
Will result in:
str : [Tilt::StringTemplate]
erb : [Tilt::ErubisTemplate, Tilt::ERBTemplate]
rhtml : [Tilt::ErubisTemplate, Tilt::ERBTemplate]
erubis : [Tilt::ErubisTemplate]
etn : [Tilt::EtanniTemplate]
etanni : [Tilt::EtanniTemplate]
haml : [Tilt::HamlTemplate]
sass : [Tilt::SassTemplate]
scss : [Tilt::ScssTemplate]
less : [Tilt::LessTemplate]
rcsv : [Tilt::CSVTemplate]
coffee : [Tilt::CoffeeScriptTemplate]
nokogiri : [Tilt::NokogiriTemplate]
builder : [Tilt::BuilderTemplate]
mab : [Tilt::MarkabyTemplate]
liquid : [Tilt::LiquidTemplate]
radius : [Tilt::RadiusTemplate]
markdown : [Tilt::RedcarpetTemplate, Tilt::RedcarpetTemplate::Redcarpet2, Tilt::RedcarpetTemplate::Redcarpet1, Tilt::RDiscountTemplate, Tilt::BlueClothTemplate, Tilt::KramdownTemplate, Tilt::MarukuTemplate]
mkd : [Tilt::RedcarpetTemplate, Tilt::RedcarpetTemplate::Redcarpet2, Tilt::RedcarpetTemplate::Redcarpet1, Tilt::RDiscountTemplate, Tilt::BlueClothTemplate, Tilt::KramdownTemplate, Tilt::MarukuTemplate]
md : [Tilt::RedcarpetTemplate, Tilt::RedcarpetTemplate::Redcarpet2, Tilt::RedcarpetTemplate::Redcarpet1, Tilt::RDiscountTemplate, Tilt::BlueClothTemplate, Tilt::KramdownTemplate, Tilt::MarukuTemplate]
textile : [Tilt::RedClothTemplate]
rdoc : [Tilt::RDocTemplate]
wiki : [Tilt::WikiClothTemplate, Tilt::CreoleTemplate]
creole : [Tilt::CreoleTemplate]
mediawiki : [Tilt::WikiClothTemplate]
mw : [Tilt::WikiClothTemplate]
yajl : [Tilt::YajlTemplate]
ad : [Tilt::AsciidoctorTemplate]
adoc : [Tilt::AsciidoctorTemplate]
asciidoc : [Tilt::AsciidoctorTemplate]
html : [Tilt::PlainTemplate]
Line 2
$n=Module.new{extend Rack;a,D,S,q=Rack::Builder.new,Object.method(:define_method),/@@ *([^\n]+)\n(((?!@@)[^\n]*\n)*)/m
Breakdown:
$n = Module.new do
app = Rack::Builder.new # rename a to app
req = nil # rename q to req
Line 3
%w[get post put delete].map{|m|D.(m){|u,&b|a.map(u){run->(e){[200,{"Content-Type"=>"text/html"},[a.instance_eval(&b)]]}}}}
Breakdown:
['get','post','put','delete'].each do |method|
define_method method do |path, &block|
app.map( path ) do
run ->(env){ [200, {'Content-Type'=>'text/html'}, [app.instance_eval( &block )]]}
end
end
end
Line 4
Tilt.mappings.map{|k,v|D.(k){|n,*o|$t||=(h=$u._jisx0301("hash, please");File.read(caller[0][/^[^:]+/]).scan(S){|a,b|h[a]=b};h);v[0].new(*o){n=="#{n}"?n:$t[n.to_s]}.render(a,o[0].try(:[],:locals)||{})}}
Breakdown:
Tilt.mappings.each do |ext, engines| # rename k to ext and v to engines
define_method ext do |text, *args| # rename n to text and o to args
template = engines[0].new(*args) do
text
end
locals = (args[0].respond_to?(:[]) ? args[0][:locals] : nil) || {} # was o[0].try(:[],:locals)||{}
template.render( app, locals )
end
end
Commentary: Almost Sinatra will define a method for every format so you can use, for example:
markdown "Strong emphasis, aka bold, with **asterisks** or __underscores__."
or
erb "Hello <%= name %>!", locals: { name: params['name'] }
Line 5
%w[set enable disable configure helpers use register].map{|m|D.(m){|*_,&b|b.try :[]}};END{Rack::Handler.get("webrick").run(a,Port:$z){|s|$r=s}}
Breakdown:
# was END { ... }; change to run! method
define_method 'run!' do
Rack::Handler.get('webrick').run( app, Port:$port ) {|server| $server=server }
end
Line 6
%w[params session].map{|m|D.(m){q.send m}};a.use Rack::Session::Cookie;a.use Rack::Lock;D.(:before){|&b|a.use Rack::Config,&b};before{|e|q=Rack::Request.new e;q.params.dup.map{|k,v|params[k.to_sym]=v}}}
Breakdown:
['params','session'].each do |method|
define_method method do
req.send method
end
end
app.use Rack::Session::Cookie
app.use Rack::Lock
app.use Rack::Config do |env|
req = Rack::Request.new( env )
end
end # Module.new
The Proof of the Pudding - hello.rb
samples/hello.rb:
require 'almost-sinatra'
include $n # include "anonymous" Almost Sinatra DSL module
get '/hello' do
erb "Hello <%= name %>!", locals: { name: params['name'] }
end
get '/' do
markdown <<EOS
## Welcome to Almost Sinatra
A six line ruby hack by Konstantin Haase.
Try:
- [Say hello!](/hello?name=Nancy)
Powered by Almost Sinatra (#{Time.now})
EOS
end
run!
Use
$ ruby -I ./lib ./samples/hello.rb
Got Inspired? Build Your Own Microframework
- New York, New York
- Nancy
- Rum
- Cuba
- Roda
- and many more
Real World Case Study - webservice library - (Yet Another) HTTP JSON API (Web Service) Builder
Micro “framework” for building HTTP JSON APIs (about 100 lines of code). Example:
get '/beer/:key' do
Beer.find_by_key! params[ :key ]
end
get '/brewery/:key' do
Brewery.find_by_key! params[ :key ]
end
Links, Links, Links
- Decoding Almost Sinatra by Rob Miller
- Code Safari: Almost Sinatra, Almost Readable by Xavier Shay
- tilt library - let’s build (yet another) micro web framework in less than 33 lines of code by Gerald Bauer
Bonus: Fun Almost Sinatra Obfuscation Hacks
“Calculate” the Sinatra Port 4567:
(Date.new.year + 145).abs # Date.new.year always returns -4712, the default value for years
# => 4567
“Get” empty Hash (e.g. {}):
Date._jisx0301("hash, please")
# => {}
2. webservice - Script (Micro) Web Services (HTTP JSON APIs); Load (Micro) Web Services At-Runtime and More
Get a free wiener lager, welsh red ale or kriek lambic beer delivered to your home (computer) in JSON and much much more
github: rubylibs/webservice, rubygems: webservice, rdoc: webservice ++ more: comments on reddit, please!
What’s the webservice library?
The webservice library lets you script HTTP JSON APIs also known as
web services or microservices in classy Sinatra 2.0-style get / post methods
with Mustermann 1.0 route / url pattern matching.
Dynamic Example
You can load web services at-runtime from files using Webservice.load_file.
Example:
# service.rb
get '/' do
'Hello, world!'
end
and
# server.rb
require 'webservice'
App = Webservice.load_file( './service.rb' )
App.run!
and to run type
$ ruby ./server.rb
Classic Example
# server.rb
require 'webservice'
class App < Webservice::Base
get '/' do
'Hello, world!'
end
end
App.run!
and to run type
$ ruby ./server.rb
Rackup Example
Use config.ru and rackup. Example:
# config.ru
require `webservice`
class App < Webservice::Base
get '/' do
'Hello, world!'
end
end
run App
and to run type
$ rackup # will (auto-)load config.ru
Note: config.ru is a shortcut (inline)
version of Rack::Builder.new do ... end:
# server.rb
require 'webservice'
class App < Webservice::Base
get '/' do
'Hello, world!'
end
end
builder = Rack::Builder.new do
run App
end
Rack::Server.start builder.to_app
and to run type
$ ruby ./server.rb
Bonus - “Real World” Examples
See
beerkit / beer.db.service -
beer.db HTTP JSON API (web service) scripts e.g.
get '/beer/(r|rnd|rand|random)' do # special keys for random beer
Beer.rnd
end
get '/beer/:key'
Beer.find_by! key: params['key']
end
get '/brewery/(r|rnd|rand|random)' do # special keys for random brewery
Brewery.rnd
end
get '/brewery/:key'
Brewery.find_by! key: params['key']
end
...
worlddb / world.db.service -
world.db HTTP JSON API (web service) scripts
get '/countries(.:format)?' do
Country.by_key.all # sort/order by key
end
get '/cities(.:format)?' do
City.by_key.all # sort/order by key
end
get '/tag/:slug(.:format)?' do # e.g. /tag/north_america.csv
Tag.find_by!( slug: params['slug'] ).countries
end
...
sportdb / sport.db.service -
sport.db (football.db) HTTP JSON API (web service) scripts
# to be done
...
3. worlddb - (Micro) Web Services (HTTP JSON APIs) Case Study - Seven Continents and the Countries of the World
Usage Models
Class Model Diagrams

Everything is a place.

Country Model - Example:
at = Country.find_by! key: 'at'
at.name
# => 'Austria'
at.pop
# => 8_414_638
at.area
# => 83_871
at.states.count
# => 9
at.states
# => [ 'Wien', 'Niederösterreich', 'Oberösterreich', ... ]
at.cities.by_pop
# => [ 'Wien', 'Graz', 'Linz', 'Salzburg', 'Innsbruck' ... ]
City Model - Example:
c = City.find_by! key: 'wien'
c.name
# => 'Wien'
c.country.name
# => 'Austria'
c.country.continent.name
# => 'Europe'
la = City.find_by! key: 'losangeles'
la.name
# => 'Los Angeles'
la.state.name
# => 'California'
la.state.key
# => 'ca'
la.country.name
# => 'United States'
la.country.key
# => 'us'
la.country.continent.name
# => 'North America'
Tag Model - Example:
euro = Tag.find_by! key: 'euro'
euro.countries.count
# => 17
euro.countries
# => ['Austria, 'Belgium', 'Cyprus', ... ]
flanders = Tag.find_by! key: 'flanders'
flanders.states.count
# => 5
flanders.states
# => ['Antwerpen', 'Brabant Wallon', 'Limburg', 'Oost-Vlaanderen', 'West-Vlaanderen']
flanders.states.first.country.name
# => 'Belgium'
and so on.
world.db Web Service (HTTP JSON API) Starter Sample
The worlddb web service starter sample lets you build your own HTTP JSON API
using the
world.db. Example:
class StarterApp < Webservice::Base
#####################
# Models
include WorldDb::Models # e.g. Continent, Country, State, City, etc.
##############################################
# Controllers / Routing / Request Handlers
get '/countries(.:format)?' do
Country.by_key.all # sort/order by key
end
get '/cities(.:format)?' do
City.by_key.all # sort/order by key
end
get '/tag/:slug(.:format)?' do # e.g. /tag/north_america.csv
Tag.find_by!( slug: params['slug'] ).countries
end
...
end # class StarterApp
(Source: app.rb)
Getting Started
Step 1: Install all libraries (Ruby gems) using bundler. Type:
$ bundle install
Step 2: Copy an SQLite database e.g. world.db into your folder.
Step 3: Startup the web service (HTTP JSON API). Type:
$ ruby ./server.rb
That’s it. Open your web browser and try some services
running on your machine on port 9292 (e.g. localhost:9292). Example:
List all the world countries (in JSON - the default format):
http://localhost:9292/countries
List all the world countries (in CSV):
http://localhost:9292/countries.csv
List all the world countries (in HTML w/ simple table):
http://localhost:9292/countries.html
List all cities (in JSON):
http://localhost:9292/cities
List all cities (in CSV):
http://localhost:9292/cities.csv
List all countries tagged with north_america (in JSON):
http://localhost:9292/tag/north_america
List all countries tagged with north_america (in CSV):
http://localhost:9292/tag/north_america.csv
And so on. Now change the app.rb script to fit your needs. Be bold. Enjoy.
world.db HTTP JSON API (web service) scripts
world.db HTTP JSON API (web service) scripts
Usage
You can run any of the scripts using the worlddb command line tool. By default the serve command will look for
a script named Service or service.rb (in the working folder, that is, ./). Example:
$ worlddb serve
To run any other script - copy the script into the working folder and pass it along as an argument. Example:
$ worlddb serve starter # note: will (auto-)add the .rb extension or
$ worlddb serve starter.rb
starter.rb - Starter world.db HTTP JSON API
get '/countries(.:format)?' do
Country.by_key.all # sort/order by key
end
get '/cities(.:format)?' do
City.by_key.all # sort/order by key
end
get '/tag/:slug(.:format)?' do # e.g. /tag/north_america.csv
Tag.find_by!( slug: params['slug'] ).countries
end
(Source: world.db.service/starter.rb)
service.rb - Service world.db HTTP JSON API
get '/countries(.:format)?' do
Country.by_key.all # sort/order by key
end
get '/cities(.:format)?' do
City.by_key.all # sort/order by key
end
get '/continents(.:format)?' do
Continent.all
end
get '/tag/:slug(.:format)?' do # e.g. /tag/north_america.csv
Tag.find_by!( slug: params['slug'] ).countries
end
(Source: world.db.service/service.rb)
4. beerdb - (Micro) Web Services (HTTP JSON APIs) Case Study - Cheers, Prost, Kampai, Na zdravi, Salute, 乾杯, Skål, Egészségedre!
Cheers, Prost, Kampai, Na zdravi, Salute, 乾杯, Skål, Egészségedre!
github: beerkit/beer.db, rubygems: beerdb, rdoc: beerdb ++ more: comments on reddit, please!
What’s the beerdb library?
The beerdb library offers a ready-to-use database schema (in SQL)
and models such as - surprise, surprise -
Beer, Brewery, Brand
and friends (using the ActiveRecord object-relational mapper machinery). Example:

Let’s try the brewery model:
by = Brewery.find_by( key: 'guinness' )
by.title
#=> 'St. James's Gate Brewery / Guinness Brewery'
by.country.key
#=> 'ie'
by.country.title
#=> 'Ireland'
by.city.title
#=> 'Dublin'
by.beers.first
#=> 'Guinness', 4.2
...
Or let’s try the beer model:
b = Beer.find_by( key: 'guinness' )
b.title
#=> 'Guinness'
b.abv # that is, alcohol by volume (abv)
#=> 4.2
b.tags
#=> 'irish_dry_stout', 'dry_stout', 'stout'
b.brewery.title
#=> 'St. James's Gate Brewery / Guinness Brewery'
...
What’s it good for? Good question. Let’s build an HTTP JSON service
that serves up a Guinness Irish Stout
or a Bamberg Aecht Schlenkerla Rauchbier Märzen as JSON?
Example - GET /beer/guinness:
{
"key": "guinness",
"title": "Guinness",
"synonyms": "Guinness Draught",
"abv": "4.2",
"srm": null,
"og": null,
"tags": ["irish_dry_stout","dry_stout","stout"],
"brewery":
{
"key": "guinness",
"title": "St. James's Gate Brewery / Guinness Brewery"
},
"country":
{
"key": "ie",
"title": "Irland"
}
}
Let’s use the Sinatra-like webservice library that offers a mini language,
that is, domain-specific language (DSL)
that lets you define routes, that is, HTTP methods paired with an URL-matching pattern
and much more.
For example, you can code the GET /beer/guinness route in
the webservice library as get '/beer/guinness'.
To make it into a route for any beer lets replace the guinness beer key
with a placeholder, thus, resulting in get '/beer/:key'. Let’s run it:
service.rb:
class BeerService < Webservice::Base
include BeerDb::Models # lets (re)use the Beer, Brewery, etc. models
get '/beer/:key' do
Beer.find_by!( key: params[:key] )
end
end
That’s it. Ready to serve. Let’s boot-up the beer service with a web server (e.g. Thin) using a Rack handler. Example:
boot.rb:
require 'webservice' # note: webservice will pull in web server machinery (e.g. rack, thin, etc.)
require 'beerdb/models' # note: beerdb will pull in database access machinery (e.g. activerecord, etc.)
# database setup 'n' config
ActiveRecord::Base.establish_connection( adapter: 'sqlite3', database: './beer.db' )
require './service'
Rack::Handler::Thin.run BeerService, :Port => 9292
Try:
$ ruby ./boot.rb
Open up your browser and try http://localhost:9292/beer/guinness.
Voila. Enjoy your Guinness irish stout responsibly.
Bonus: Let’s add brewery details and more
Let’s add brewery details to the beer service and lets add a new GET /brewery route. Example:
get '/beer/:key' do
beer = Beer.find_by!( key: params[ :key ] )
brewery = {}
if beer.brewery.present?
brewery = { key: beer.brewery.key,
title: beer.brewery.title }
end
tags = []
if beer.tags.present?
beer.tags.each { |tag| tags << tag.key }
end
{ key: beer.key,
title: beer.title,
synonyms: beer.synonyms,
abv: beer.abv,
srm: beer.srm,
og: beer.og,
tags: tags,
brewery: brewery,
country: { key: beer.country.key,
title: beer.country.title }
}
end
get '/brewery/:key' do
brewery = Brewery.find_by!( key: params[:key] )
beers = []
brewery.beers.each do |b|
beers << { key: b.key, title: b.title }
end
tags = []
if brewery.tags.present?
brewery.tags.each { |tag| tags << tag.key }
end
{ key: brewery.key,
title: brewery.title,
synonyms: brewery.synonyms,
since: brewery.since,
address: brewery.address,
web: brewery.web,
tags: tags,
beers: beers,
country: { key: brewery.country.key,
title: brewery.country.title }
}
end
beer.db HTTP JSON API (web service) scripts
beer.db HTTP JSON API (web service) scripts
Usage
You can run any of the scripts using the beerdb command line tool. By default the serve command will look for
a script named Service or service.rb (in the working folder, that is, ./). Example:
$ beerdb serve
To run any other script - copy the script into the working folder and pass it along as an argument. Example:
$ beerdb serve starter # note: will (auto-)add the .rb extension or
$ beerdb serve starter.rb
starter.rb - Starter beer.db HTTP JSON API
get '/beer/(r|rnd|rand|random)' do ## special keys for random beer
Beer.rnd
end
get '/beer/:key' do
Beer.find_by! key: params['key']
end
get '/brewery/(r|rnd|rand|random)' do ## special keys for random brewery
Brewery.rnd
end
get '/brewery/:key' do
Brewery.find_by! key: params['key']
end
(Source: beer.db.service/starter.rb)
service.rb - Service beer.db HTTP JSON API
get '/' do
## self-docu in json
data = {
endpoints: {
get_beer: {
doc: 'get beer by key',
url: '/beer/:key'
},
}
}
end
get '/notes/:key' do |key|
puts " handle GET /notes/:key"
if ['l', 'latest'].include?( key )
# get latest tasting notes (w/ ratings)
notes = Note.order( 'updated_at DESC' ).limit(10).all
elsif ['h', 'hot'].include?( key )
# get latest tasting notes (w/ ratings)
# fix: use log algo for "hotness" - for now same as latest
notes = Note.order( 'updated_at DESC' ).limit(10).all
elsif ['t', 'top'].include?( key )
notes = Note.order( 'rating DESC, updated_at DESC' ).limit(10).all
else
### todo: move to /u/:key/notes ??
# assume it's a user key
user = User.find_by_key!( key )
notes = Note.order( 'rating DESC, updated_at DESC' ).where( user_id: user.id ).all
end
data = []
notes.each do |note|
data << {
beer: { title: note.beer.title,
key: note.beer.key },
user: { name: note.user.name,
key: note.user.key },
rating: note.rating,
comments: note.comments,
place: note.place,
created_at: note.created_at,
updated_at: note.updated_at
}
end
data
end
get '/notes' do
if params[:method] == 'post'
puts " handle GET /notes?method=post"
user = User.find_by_key!( params[:user] )
beer = Beer.find_by_key!( params[:beer] )
rating = params[:rating].to_i
place = params[:place] # assumes for now a string or nil / pass through as is
attribs = {
user_id: user.id,
beer_id: beer.id,
rating: rating,
place: place
}
note = Note.new
note.update_attributes!( attribs )
end
{ status: 'ok' }
end
get '/drinks/:key' do |key|
puts " handle GET /drinks/:key"
if ['l', 'latest'].include?( key )
# get latest +1 drinks
## todo: order by drunk_at??
drinks = Drink.order( 'updated_at DESC' ).limit(10).all
else
### todo: move to /u/:key/drinks ??
# assume it's a user key
user = User.find_by_key!( key )
drinks = Drink.order( 'updated_at DESC' ).where( user_id: user.id ).all
end
data = []
drinks.each do |drink|
data << {
beer: { title: drink.beer.title,
key: drink.beer.key },
user: { name: drink.user.name,
key: drink.user.key },
place: drink.place,
drunk_at: drink.drunk_at,
created_at: drink.created_at,
updated_at: drink.updated_at
}
end
data
end
get '/drinks' do
if params[:method] == 'post'
puts " handle GET /drinks?method=post"
user = User.find_by_key!( params[:user] )
beer = Beer.find_by_key!( params[:beer] )
place = params[:place] # assumes for now a string or nil / pass through as is
attribs = {
user_id: user.id,
beer_id: beer.id,
place: place
}
drink = Drink.new
drink.update_attributes!( attribs )
end
{ status: 'ok' }
end
get '/beer/:key' do |key|
if ['r', 'rnd', 'rand', 'random'].include?( key )
# special key for random beer
# Note: use .first (otherwise will get ActiveRelation not Model)
beer = Beer.rnd.first
else
beer = Beer.find_by_key!( key )
end
end
get '/brewery/:key' do |key|
if ['r', 'rnd', 'rand', 'random'].include?( key )
# special key for random brewery
# Note: use .first (otherwise will get ActiveRelation not Model)
brewery = Brewery.rnd.first
else
brewery = Brewery.find_by_key!( key )
end
end
(Source: beer.db.service/service.rb)
5. sportdb - (Micro) Web Services (HTTP JSON APIs) Case Study - The World's Biggest Event - Russia 2018 - Football World Cup
World Cup - English Premier League - Spanish La Liga - Austrian Bundesliga :-) And Much More
github: sportdb/sport.db, rubygems: sportdb, rdoc: sportdb ++ more: comments on reddit, please!
What’s sportdb?
A library and command line tool that ships with an ready-to-use sport.db SQL schema and ActiveRecord models and (structured) text-to-data readers (parsers).
Usage Models
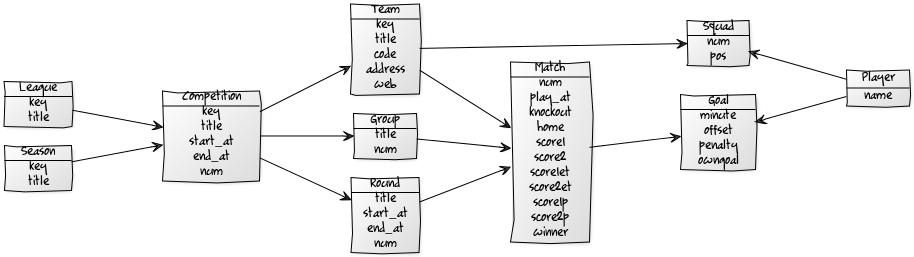
Quick Starter Sample - Kick Off
Let’s get started with the Quick Starter Sample. Welcome to the Mauritius Premier Football League. Lets create your own (structured) text datasets from scratch and read it all into your SQL database of choice (e.g. SQLite, PostgreSQL, etc.) with a single command e.g.:
$ sportdb build
Let’s get started. Follow along these six steps:
- Step 1: Add all leagues
- Step 2: Add all clubs
- Step 3: Add all match fixtures and results
- Step 4: Add the league season “front matter” settings
- Step 5: Add a setups file list (also known as manifest)
- Step 6: Add a datafile build script - That’s it. Done.
Using a file structure like:
├── 2014-15 # 2014-15 season folder
| ├── league-i.txt # match fixtures / results - matchdays 1-18
| ├── league-ii.txt # - matchdays 19-36
| └── league.yml # "front matter" settings
├── setups
| └── all.txt # file list (manifest)
├── leagues.txt # all leagues
├── clubs.txt # all clubs
└── Datafile # build script
Step 1: Add all leagues
Example - leagues.txt:
mu, Mauritius Premier League
Step 2: Add all clubs
The Mauritius Premier League includes ten clubs.
Example - clubs.txt:
joachim, Cercle de Joachim|Cercle de Joachim SC|Joachim, CDJ
chamarel, Chamarel|Chamarel SC, CHA
curepipesc, Curepipe Starlight|Curepipe SC|Starlight, CUR
entente, Entente Boulet Rouge|Entente Boulet Rouge-Riche Mare Rovers, EBR
lacure, La Cure Sylvester|La Cure, LCS
pamplemousses, Pamplemousses|Pamplemousses SC, PPM
petiteriv, Petite Rivière Noire|Petite Rivière, PRN
aspl, AS Port-Louis 2000|ASPL 2000, APL
qbornes, AS Quatre Bornes|Quatre Bornes, AQB
rempart, AS Rivière du Rempart|Rivière du Rempart, ARR
Note: Use the pipe (|) to list alternative names.
Step 3: Add all match fixtures and results
Example - 2014-15/league-i.txt:
Matchday 1
[Wed Nov/5]
Curepipe Starlight 1-3 Petite Rivière Noire
AS Quatre Bornes 1-0 La Cure Sylvester
Pamplemousses 0-1 Rivière du Rempart
AS Port-Louis 2000 5-1 Entente Boulet Rouge
Chamarel FC 2-3 Cercle de Joachim
Matchday 2
[Sun Nov/9]
Curepipe Starlight 2-1 AS Quatre Bornes
Entente Boulet Rouge 1-2 Chamarel FC
Rivière du Rempart 1-1 AS Port-Louis 2000
La Cure Sylvester 1-2 Pamplemousses
Petite Rivière Noire 2-0 Cercle de Joachim
Matchday 3
[Wed Nov/12]
Chamarel FC 1-1 Rivière du Rempart
AS Port-Louis 2000 1-0 La Cure Sylvester
Cercle de Joachim 2-2 Entente Boulet Rouge
Pamplemousses 0-4 Curepipe Starlight
AS Quatre Bornes 1-2 Petite Rivière Noire
Matchday 4
[Sun Nov/16]
Petite Rivière Noire 4-1 Entente Boulet Rouge
Rivière du Rempart 1-1 Cercle de Joachim
La Cure Sylvester 0-0 Chamarel FC
Curepipe Starlight 0-0 AS Port-Louis 2000
AS Quatre Bornes 1-0 Pamplemousses
...
Step 4: Add the league season “front matter” settings
Example - 2014-15/league.yml:
league: mu
season: 2014/15
start_at: 2014-11-05
fixtures:
- league-i
- league-ii
10 teams:
- Cercle de Joachim
- AS Port-Louis 2000
- Pamplemousses
- Curepipe Starlight
- Petite Rivière Noire
- Rivière du Rempart
- AS Quatre Bornes
- Chamarel SC
- La Cure Sylvester
- Entente Boulet Rouge
Step 5: Add a setups file list (also known as manifest)
Example - setups/all.txt:
mu-mauritius!/leagues
mu-mauritius!/clubs
mu-mauritius!/2014-15/league
Step 6: Add a datafile build script - That’s it. Done.
Example - Datafile:
## a) Add country e.g. Mauritius
inline do
Country.parse 'mu', 'Mauritius', 'MUS', '2_040 km²', '1_261_200'
end
## b) Read in all football datasets in ./mu-mauritius (defaults to setups/all.txt)
football 'mu-mauritius'
Now try in your working folder:
$ sportdb build
This will read in the ./Datafile and
- setup a new single-file SQLite database e.g.
./sport.db - read in all plain text datasets
That’s it. Try:
$ sqlite3 sport.db
SQLite version 3.7.16
Enter ".help" for instructions
Enter SQL statements terminated with a ";"
sqlite> .tables
alltime_standing_entries events_grounds names
alltime_standings events_teams parts
assocs games persons
assocs_assocs goals places
badges grounds props
cities group_standing_entries rosters
continents group_standings rounds
counties groups seasons
countries groups_teams states
country_codes langs taggings
districts leagues tags
event_standing_entries logs teams
event_standings metros usages
events munis zones
sqlite> select * from countries;
1|Mauritius|mauritius|mu|1|MUS|||1261200|2040|||f|t|f|f|
sqlite> select * from teams;
1|joachim|Cercle de Joachim||CDJ|Cercle de Joachim SC|Joachim||t|||||f|
2|chamarel|Chamarel SC||CHA|Chamarel|Chamarel Sport Club||t|||||f|
3|curepipesc|Curepipe Starlight||CUR|Curepipe Starlight SC||t|||||f|
4|entente|Entente Boulet Rouge||EBR|Entente Boulet Rouge SC|Entente Boulet Rouge-Riche Mare Rovers||t|||||f|
5|lacure|La Cure Sylvester||LCS|La Cure Sylvester SC|La Cure||t|||||f|
6|pamplemousses|Pamplemousses||PPM|Pamplemousses SC||t|||||f|
7|petiteriv|Petite Rivière Noire||PRN|Petite Rivière Noire SC|Petite Rivière||t|||||f|
8|aspl|AS Port-Louis 2000||APL|ASPL 2000|Port-Louis 2000|Association Sportive Port-Louis 2000||t|||||f|
9|qbornes|AS Quatre Bornes||AQB|ASQB|Quatre Bornes||t|||||f|
10|rempart|Rivière du Rempart||ARR|AS Rivière du Rempart||t|||||f|
11|pointauxsables|Pointe-aux-Sables Mates|||||t|||||f|
12|savanne|Savanne SC|||Savanne Sporting Club||t|||||f|
And so on.
Bonus: Football World Cup 2018 - Russia 2018 Datasets
In the openfootball/world-cup you find ready-to-use (free, public domain) datasets for all world cups including the upcoming world cup 2018 in Russia. Example - 2018–russia/cup.txt:
############################
# World Cup 2018 Russia
Group A | Russia Saudi Arabia Egypt Uruguay
Group B | Portugal Spain Morocco Iran
Group C | France Australia Peru Denmark
Group D | Argentina Iceland Croatia Nigeria
Group E | Brazil Switzerland Costa Rica Serbia
Group F | Germany Mexico Sweden South Korea
Group G | Belgium Panama Tunisia England
Group H | Poland Senegal Colombia Japan
Matchday 1 | Thu Jun/14
Matchday 2 | Fri Jun/15
Matchday 3 | Sat Jun/16
...
Group A:
(1) Thu Jun/14 18:00 Russia - Saudi Arabia @ Luzhniki Stadium, Moscow (UTC+3)
(2) Fri Jun/15 17:00 Egypt - Uruguay @ Central Stadium, Yekaterinburg (UTC+5)
...
6. feedparser - Meet Jason Feed - The Universal Content (Micro) Web Service (HTTP JSON API) - The Future of Publishing 'n' Online News
The Future of Online News - The Future of Facebook & Co - Web Feeds, Web Feeds, Web Feeds
github: feedparser/feedparser, rubygems: feedparser, rdoc: feedparser ++ more: comments on reddit, please!
What’s a web feed?
A web feed (or news feed) is a (simple) document/text format that:
(1) lets you publish a list of:
- status updates, blog postings, articles, pictures, cartoons, recordings, etc.
and that
(2) lets others subscribe to your updates.
Example:
{
"version": "https://jsonfeed.org/version/1",
"title": "Jason Fried's Microblog",
"home_page_url": "https://micro.blog/jasonfried/",
"feed_url": "https://micro.blog/jasonfried/feed.json",
"author": {
"name": "Jason Fried",
"url": "https://micro.blog/jasonfried/",
"avatar": "https://micro.blog/jasonfried/avatar.png"
},
"items": [
{
"id": "865767227416612864",
"url": "https://micro.blog/jasonfried/status/865767227416612864",
"content_text": "JSON Feed? I know that guy.",
"date_published": "2017-05-19T20:12:00-00:00"
}
]
}
Aside: The Wonders of RSS - What’s RSS!?
Triva Quiz - Q: What’s RSS?
- [A] RDF Site Summary
- [B] Rich Site Summary
- [C] Really Simple Syndication
- [D] Really Simple, Stupid
- [E] Rapid Syndicaton Solution
RDF = Resource Description Framework
Trivia Quiz - Find the Content - Q: What’s your favorite way to add content in hypertext to RSS 2.0?
- [A]
<description> - [B]
<content:encoded>from RDF/RSS 1.0 content module extension - [C]
<media:content>from Yahoo! search extension - [D] Other? Please, tell!
Bonus: Is your content in plain text, in html, in xhtml, in html escaped? Is your content a summary? or full text?
The State of Web Feed Formats in 2017 - XML, JSON, YAML, HTML, TXT
Let’s celebrate diversity! Live and let live! Web feed formats today in 2017 include:
- RSS 2.0 (0.91, 0.92) a.k.a. Really Simple Syndication - in XML
- RSS 1.0 a.k.a. RDF Site Summary - in RDF/XML
- Atom - in XML
- JSON Feed - in - surprise, surprise - JSON
- Microformats (h-feed/h-entry) - in HTML
- Feed.TXT - in plain text; metadata in (simplified) YAML or JSON; Markdown
And some more.
What’s the feedparser library?
One library to rule them all! All your base are blong to feedparser.
In the end all formats are just 0 and 1s or:
feed.titlefeed.urlfeed.items[0].titlefeed.items[0].urlfeed.items[0].publishedfeed.items[0].content_htmlorfeed.items[0].contentfeed.items[0].content_textfeed.items[0].summary- etc.
=> Let your computer handle the reading of web feeds ;-).
Read Feed Example
require 'open-uri'
require 'feedparser'
txt = open( 'http://openfootball.github.io/feed.xml' ).read
feed = FeedParser::Parser.parse( txt )
puts feed.title
# => "football.db - Open Football Data"
puts feed.url
# => "http://openfootball.github.io/"
puts feed.items[0].title
# => "football.db - League Quick Starter Sample - Mauritius Premier League - Create Your Own Repo/League(s) from Scratch"
puts feed.items[0].url
# => "http://openfootball.github.io/2015/08/30/league-quick-starter.html"
puts feed.items[0].updated
# => Sun, 30 Aug 2015 00:00:00 +0000
puts feed.items[0].content
# => "Added a new quick starter sample using the Mauritius Premier League to get you started..."
...
or reading a feed in the new JSON Feed format in - surprise, surprise - JSON; note: nothing changes :-)
txt = open( 'http://openfootball.github.io/feed.json' ).read
feed = FeedParser::Parser.parse( txt )
puts feed.title
# => "football.db - Open Football Data"
puts feed.url
# => "http://openfootball.github.io/"
puts feed.items[0].title
# => "football.db - League Quick Starter Sample - Mauritius Premier League - Create Your Own Repo/League(s) from Scratch"
puts feed.items[0].url
# => "http://openfootball.github.io/2015/08/30/league-quick-starter.html"
puts feed.items[0].updated
# => Sun, 30 Aug 2015 00:00:00 +0000
puts feed.items[0].content_text
# => "Added a new quick starter sample using the Mauritius Premier League to get you started..."
...
Microformats
Microformats let you mark up feeds and posts in HTML with
h-entry,
h-feed,
and friends.
Note: Microformats support in feedparser is optional. Install and require the the microformats library to read feeds in HTML with Microformats.
require 'microformats'
text =<<HTML
<article class="h-entry">
<h1 class="p-name">Microformats are amazing</h1>
<p>Published by
<a class="p-author h-card" href="http://example.com">W. Developer</a>
on <time class="dt-published" datetime="2013-06-13 12:00:00">13<sup>th</sup> June 2013</time>
<p class="p-summary">In which I extoll the virtues of using microformats.</p>
<div class="e-content">
<p>Blah blah blah</p>
</div>
</article>
HTML
feed = FeedParser::Parser.parse( text )
puts feed.format
# => "html"
puts feed.items.size
# => 1
puts feed.items[0].authors.size
# => 1
puts feed.items[0].content_html
# => "<p>Blah blah blah</p>"
puts feed.items[0].content_text
# => "Blah blah blah"
puts feed.items[0].title
# => "Microformats are amazing"
puts feed.items[0].summary
# => "In which I extoll the virtues of using microformats."
puts feed.items[0].published
# => 2013-06-13 12:00:00
puts feed.items[0].authors[0].name
# => "W. Developer"
...
Samples
Feed Reader
Planet Feed Reader in 20 Lines of Ruby
planet.rb:
require 'open-uri'
require 'feedparser'
require 'erb'
# step 1) read a list of web feeds
FEED_URLS = [
'http://vienna-rb.at/atom.xml',
'http://weblog.rubyonrails.org/feed/atom.xml',
'http://www.ruby-lang.org/en/feeds/news.rss',
'http://openfootball.github.io/feed.json',
]
items = []
FEED_URLS.each do |url|
feed = FeedParser::Parser.parse( open( url ).read )
items += feed.items
end
# step 2) mix up all postings in a new page
FEED_ITEM_TEMPLATE = <<EOS
<% items.each do |item| %>
<div class="item">
<h2><a href="<%= item.url %>"><%= item.title %></a></h2>
<div><%= item.content %></div>
</div>
<% end %>
EOS
puts ERB.new( FEED_ITEM_TEMPLATE ).result
Run the script:
$ ruby ./planet.rb
Prints:
<div class="item">
<h2><a href="http://vienna-rb.at/blog/2017/11/06/picks/">Picks / what the vienna.rb team thinks is worth sharing this week</a></h2>
<div>
<h3>6/11 Picks!!</h3>
<p>In a series on this website we'll entertain YOU with our picks...
...
Real World Usage
See the Planet Pluto feed reader family:
- Planet Pluto - static planet website generator
- Planet Pluto Live - dynamic (live) planet web apps (using Sinatra, Rails, etc.)
7. json-next - Comments, Please! - JSON 1.0, JSON 1.1, JSON What's Next?
HANSON.parse, SON.parse, JSONX.parse
github: json-next/json-next, rubygems: json-next, rdoc: json-next ++ more: comments on reddit, please!
What’s missing in JSON?
- Comments, Comments, Comments
- Unquoted Keys
- Multi-Line Strings
- a) Folded – Folds Newlines
- b) Unfolded
- Trailing Commas in Arrays and Objects
More:
- Date/DateTime/Timestamp Type
- Optional Commas
- Optional Unquoted String Values
- “Raw” String (e.g.
''instead of"")- No need to escape
\or"etc. To escape'use'''e.g.''''Henry's Themes'''
- No need to escape
- More Data Types (
set,map,symbol, etc.) - And much more
Discussion
Fixing JSON - Comments, Please!
We can easily agree on what’s wrong with JSON, and I can’t help wondering if it’d be worth fixing it.
– Tim Bray (Fixing JSON)
XML already does everything JSON does! And there’s no way to differentiate between nodes and attributes! And there are no namespaces! And no schemas! What’s the point of JSON?
– Anonymous
We need to fix engineers that try to ‘fix JSON’, absolutely nothing is broken with JSON.
– Anonymous
What’s the json-next library?
The json-next library lets you convert and read (parse) next generation json versions
including: HanSON e.g. HANSON.parse, SON e.g. SON.parse, JSONX e.g. JSONX.parse.
HanSON
HanSON - JSON for Humans by Tim Jansen et al
HanSON is an extension of JSON with a few simple additions to the spec:
- quotes for strings are optional if they follow JavaScript identifier rules.
- you can alternatively use backticks, as in ES6’s template string literal, as quotes for strings. A backtick-quoted string may span several lines and you are not required to escape regular quote characters, only backticks. Backslashes still need to be escaped, and all other backslash-escape sequences work like in regular JSON.
- for single-line strings, single quotes (
'') are supported in addition to double quotes ("") - you can use JavaScript comments, both single line (
//) and multi-line comments (/* */), in all places where JSON allows whitespace. - Commas after the last list element or object property will be ignored.
Example:
{
listName: "Sesame Street Monsters", // note that listName needs no quotes
content: [
{
name: "Cookie Monster",
/* Note the template quotes and unescaped regular quotes in the next string */
background: `Cookie Monster used to be a
monster that ate everything, especially cookies.
These days he is forced to eat "healthy" food.`
}, {
// You can single-quote strings too:
name: 'Herry Monster',
background: `Herry Monster is a furry blue monster with a purple nose.
He's mostly retired today.`
}, // don't worry, the trailing comma will be ignored
]
}
Use HANSON.convert to convert HanSON text to ye old’ JSON text:
{
"listName": "Sesame Street Monsters",
"content": [
{ "name": "Cookie Monster",
"background": "Cookie Monster used to be a\n ... to eat \"healthy\" food."
},
{ "name": "Herry Monster",
"background": "Herry Monster is a furry blue monster with a purple nose.\n ... today."
}
]
}
Use HANSON.parse instead of JSON.parse to parse text to ruby hash / array / etc.:
{
"listName" => "Sesame Street Monsters",
"content" => [
{ "name" => "Cookie Monster",
"background" => "Cookie Monster used to be a\n ... to eat \"healthy\" food."
},
{ "name" => "Herry Monster",
"background" => "Herry Monster is a furry blue monster with a purple nose.\n ... today."
}
]
}
SON
SON - Simple Object Notation by Aleksander Gurin et al
Simple data format similar to JSON, but with some minor changes:
- comments starts with
#sign and ends with newline (\n) - comma after an object key-value pair is optional
- comma after an array item is optional
JSON is compatible with SON in a sense that JSON data is also SON data, but not vise versa.
Example:
{
# Personal information
"name": "Alexander Grothendieck"
"fields": "mathematics"
"main_topics": [
"Etale cohomology"
"Motives"
"Topos theory"
"Schemes"
]
"numbers": [1 2 3 4]
"mixed": [1.1 -2 true false null]
}
Use SON.convert to convert SON text to ye old’ JSON text:
{
"name": "Alexander Grothendieck",
"fields": "mathematics",
"main_topics": [
"Etale cohomology",
"Motives",
"Topos theory",
"Schemes"
],
"numbers": [1, 2, 3, 4],
"mixed": [1.1, -2, true, false, null]
}
Use SON.parse instead of JSON.parse to parse text to ruby hash / array / etc.:
{
"name" => "Alexander Grothendieck",
"fields" => "mathematics",
"main_topics" =>
["Etale cohomology", "Motives", "Topos theory", "Schemes"],
"numbers" => [1, 2, 3, 4],
"mixed" => [1.1, -2, true, false, nil]
}
JSONX
JSON with Extensions or JSON v1.1 (a.k.a. JSON11 or JSON XI or JSON II)
Includes all JSON extensions from HanSON:
- quotes for strings are optional if they follow JavaScript identifier rules.
- you can alternatively use backticks, as in ES6’s template string literal, as quotes for strings. A backtick-quoted string may span several lines and you are not required to escape regular quote characters, only backticks. Backslashes still need to be escaped, and all other backslash-escape sequences work like in regular JSON.
- for single-line strings, single quotes (
'') are supported in addition to double quotes ("") - you can use JavaScript comments, both single line (
//) and multi-line comments (/* */), in all places where JSON allows whitespace. - Commas after the last list element or object property will be ignored.
Plus all JSON extensions from SON:
- comments starts with
#sign and ends with newline (\n) - comma after an object key-value pair is optional
- comma after an array item is optional
Plus some more extra JSON extensions:
- unquoted strings following the JavaScript identifier rules can use the dash (
-) too e.g. allows common keys such ascore-js,babel-preset-es2015,eslint-config-jqueryand others
Example:
{
# use shell-like (or ruby-like) comments
listName: "Sesame Street Monsters" # note: comments after key-value pairs are optional
content: [
{
name: "Cookie Monster"
// note: the template quotes and unescaped regular quotes in the next string
background: `Cookie Monster used to be a
monster that ate everything, especially cookies.
These days he is forced to eat "healthy" food.`
}, {
// You can single-quote strings too:
name: 'Herry Monster',
background: `Herry Monster is a furry blue monster with a purple nose.
He's mostly retired today.`
}, /* don't worry, the trailing comma will be ignored */
]
}
Use JSONX.convert (or JSONXI.convert or JSON11.convert or JSONII.convert) to convert JSONX text to ye old’ JSON text:
{
"listName": "Sesame Street Monsters",
"content": [
{ "name": "Cookie Monster",
"background": "Cookie Monster used to be a\n ... to eat \"healthy\" food."
},
{ "name": "Herry Monster",
"background": "Herry Monster is a furry blue monster with a purple nose.\n ... today."
}
]
}
Use JSONX.parse (or JSONXI.parse or JSON11.parse or JSONII.parse) instead of JSON.parse to parse text to ruby hash / array / etc.:
{
"listName" => "Sesame Street Monsters",
"content" => [
{ "name" => "Cookie Monster",
"background" => "Cookie Monster used to be a\n ... to eat \"healthy\" food."
},
{ "name" => "Herry Monster",
"background" => "Herry Monster is a furry blue monster with a purple nose.\n ... today."
}
]
}
Live Examples
require 'json/next'
text1 =<<TXT
{
listName: "Sesame Street Monsters", // note that listName needs no quotes
content: [
{
name: "Cookie Monster",
/* Note the template quotes and unescaped regular quotes in the next string */
background: `Cookie Monster used to be a
monster that ate everything, especially cookies.
These days he is forced to eat "healthy" food.`
}, {
// You can single-quote strings too:
name: 'Herry Monster',
background: `Herry Monster is a furry blue monster with a purple nose.
He's mostly retired today.`
}, // don't worry, the trailing comma will be ignored
]
}
TXT
pp HANSON.parse( text1 ) # note: is the same as JSON.parse( HANSON.convert( text ))
resulting in:
{
"listName" => "Sesame Street Monsters",
"content" => [
{ "name" => "Cookie Monster",
"background" => "Cookie Monster used to be a\n ... to eat \"healthy\" food."
},
{ "name" => "Herry Monster",
"background" => "Herry Monster is a furry blue monster with a purple nose.\n ... today."
}
]
}
and
text2 =<<TXT
{
# Personal information
"name": "Alexander Grothendieck"
"fields": "mathematics"
"main_topics": [
"Etale cohomology"
"Motives"
"Topos theory"
"Schemes"
]
"numbers": [1 2 3 4]
"mixed": [1.1 -2 true false null]
}
TXT
pp SON.parse( text2 ) # note: is the same as JSON.parse( SON.convert( text ))
resulting in:
{
"name" => "Alexander Grothendieck",
"fields" => "mathematics",
"main_topics" =>
["Etale cohomology", "Motives", "Topos theory", "Schemes"],
"numbers" => [1, 2, 3, 4],
"mixed" => [1.1, -2, true, false, nil]
}
and
text3 =<<TXT
{
# use shell-like (or ruby-like) comments
listName: "Sesame Street Monsters" # note: comments after key-value pairs are optional
content: [
{
name: "Cookie Monster"
// note: the template quotes and unescaped regular quotes in the next string
background: `Cookie Monster used to be a
monster that ate everything, especially cookies.
These days he is forced to eat "healthy" food.`
}, {
// You can single-quote strings too:
name: 'Herry Monster',
background: `Herry Monster is a furry blue monster with a purple nose.
He's mostly retired today.`
}, /* don't worry, the trailing comma will be ignored */
]
}
TXT
pp JSONX.parse( text3 ) # note: is the same as JSON.parse( JSONX.convert( text ))
pp JSONXI.parse( text3 ) # note: is the same as JSON.parse( JSONXI.convert( text ))
pp JSON11.parse( text3 ) # note: is the same as JSON.parse( JSON11.convert( text ))
pp JSONII.parse( text3 ) # note: is the same as JSON.parse( JSONII.convert( text ))
resulting in:
{
"listName" => "Sesame Street Monsters",
"content" => [
{ "name" => "Cookie Monster",
"background" => "Cookie Monster used to be a\n ... to eat \"healthy\" food."
},
{ "name" => "Herry Monster",
"background" => "Herry Monster is a furry blue monster with a purple nose.\n ... today."
}
]
}
Bonus: More JSON Formats
See the Awesome JSON (What’s Next?) collection / page.
8. feedtxt - TXT is the new JSON Case Study - Feeds in Text (Unicode) - Publish 'n' Share Posts, Articles, Podcasts, 'n' More
github: feedtxt/feedtxt, rubygems: feedtxt, rdoc: feedtxt
Usage
Use Feedtxt.parse to read / parse feeds in text using the Feed.TXT
format also known as RSS (Really Simple Sharing) 5.0 ;-).
The parse method will return an array:
[ feed_metadata,
[
[ item_metadata, item_content ],
[ item_metadata, item_content ],
...
]
]
- The 1st element is the feed metadata hash.
- The 2nd element is the items array.
- The 1st element in an item array is the item metadata hash.
- The 2nd element in an item array is the item content.
Easier to see it in action. Let’s read in:
require 'feedtxt'
text =<<TXT
|>>>
title: "My Example Feed"
home_page_url: "https://example.org/"
feed_url: "https://example.org/feed.txt"
</>
id: "2"
url: "https://example.org/second-item"
---
This is a second item.
</>
id: "1"
url: "https://example.org/initial-post"
---
Hello, world!
<<<|
TXT
feed = Feedtxt.parse( text )
pp feed
resulting in:
[
{"title" =>"My Example Feed",
"home_page_url"=>"https://example.org/",
"feed_url" =>"https://example.org/feed.txt"
},
[[
{"id" =>"2",
"url"=>"https://example.org/second-item"
},
"This is a second item."
],
[
{"id"=>"1",
"url"=>"https://example.org/initial-post"
},
"Hello, world!"
]]
]
and use like:
feed_metadata = feed[0]
feed_items = feed[1]
feed_metadata[ 'title' ]
# => "My Example Feed"
feed_metadata[ 'feed_url' ]
# => "https://example.org/feed.txt"
item = feed_items[0] # or feed[1][0]
item_metadata = item[0] # or feed[1][0][0]
item_content = item[1] # or feed[1][0][1]
item_metadata[ 'id' ]
# => "2"
item_metadata[ 'url' ]
# => "https://example.org/second-item"
item_content
# => "This is a second item."
item = feed_items[1] # or feed[1][1]
item_metadata = item[0] # or feed[1][1][0]
item_content = item[1] # or feed[1][1][1]
item_metadata[ 'id' ]
# => "1"
item_metadata[ 'url' ]
# => "https://example.org/initial-post"
item_content
# => "Hello, world!"
...
Another example. Let’s try a podcast:
text =<<TXT
|>>>
comment: "This is a podcast feed. You can add..."
title: "The Record"
home_page_url: "http://therecord.co/"
feed_url: "http://therecord.co/feed.txt"
</>
id: "http://therecord.co/chris-parrish"
title: "Special #1 - Chris Parrish"
url: "http://therecord.co/chris-parrish"
summary: "Brent interviews Chris Parrish, co-host of The Record and one-half of Aged & Distilled."
published: 2014-05-09T14:04:00-07:00
attachments:
- url: "http://therecord.co/downloads/The-Record-sp1e1-ChrisParrish.m4a"
mime_type: "audio/x-m4a"
size_in_bytes: 89970236
duration_in_seconds: 6629
---
Chris has worked at [Adobe][1] and as a founder of Rogue Sheep, which won an Apple Design Award for Postage.
Chris's new company is Aged & Distilled with Guy English - which shipped [Napkin](2),
a Mac app for visual collaboration. Chris is also the co-host of The Record.
He lives on [Bainbridge Island][3], a quick ferry ride from Seattle.
[1]: http://adobe.com/
[2]: http://aged-and-distilled.com/napkin/
[3]: http://www.ci.bainbridge-isl.wa.us/
<<<|
TXT
feed = Feedtxt.parse( text )
pp feed
resulting in:
[{"comment"=>"This is a podcast feed. You can add...",
"title"=>"The Record",
"home_page_url"=>"http://therecord.co/",
"feed_url"=>"http://therecord.co/feed.txt"
},
[
[{"id"=>"http://therecord.co/chris-parrish",
"title"=>"Special #1 - Chris Parrish",
"url"=>"http://therecord.co/chris-parrish",
"summary"=>"Brent interviews Chris Parrish, co-host of The Record and...",
"published"=>2014-05-09 23:04:00 +0200,
"attachments"=>
[{"url"=>"http://therecord.co/downloads/The-Record-sp1e1-ChrisParrish.m4a",
"mime_type"=>"audio/x-m4a",
"size_in_bytes"=>89970236,
"duration_in_seconds"=>6629}]
},
"Chris has worked at [Adobe][1] and as a founder of Rogue Sheep..."
]
]
]
and use like:
feed_metadata = feed[0]
feed_items = feed[1]
feed_metadata[ 'title' ]
# => "The Record"
feed_metadata[ 'feed_url' ]
# => "http://therecord.co/feed.txt"
item = feed_items[0] # or feed[1][0]
item_metadata = item[0] # or feed[1][0][0]
item_content = item[1] # or feed[1][0][1]
item_metadata[ 'title' ]
# => "Special #1 - Chris Parrish"
item_metadata[ 'url' ]
# => "http://therecord.co/chris-parrish
item_content
# => "Chris has worked at [Adobe][1] and as a founder of Rogue Sheep..."
...
Alternative Meta Data Formats
Note: Feed.TXT supports alternative formats / styles for meta data blocks.
For now YAML, JSON and INI style
are built-in and shipping with the feedtxt gem.
To use a format-specific parser use:
Feedtxt::YAML.parseFeedtxt::JSON.parseFeedtxt::INI.parse
Note: Feedtxt.parse will handle all formats auto-magically,
that is, it will check the text for the best matching (first)
feed begin marker
to find out what meta data format parser to use:
| Format | FEED_BEGIN |
|---|---|
| YAML | \|>>> |
| JSON | \|{ |
| INI | [>>> |
Or use the built-in text pattern (regular expression) constants to find out:
Feedtxt::YAML::FEED_BEGIN
# => "^[ ]*\\|>>>+[ ]*$"
Feedtxt::JSON::FEED_BEGIN
# => "^[ ]*\\|{+[ ]*$"
Feedtxt::INI::FEED_BEGIN
# => "^[ ]*\\[>>>+[ ]*$"
JSON Example
|{
"title": "My Example Feed",
"home_page_url": "https://example.org/",
"feed_url": "https://example.org/feed.txt"
}/{
"id": "2",
"url": "https://example.org/second-item"
}-{
This is a second item.
}/{
"id": "1",
"url": "https://example.org/initial-post"
}-{
Hello, world!
}|
Note: Use |{ and }| to begin and end your Feed.TXT.
Use }/{ for first or next item
and }-{ for meta blocks inside items.
(Source: feeds/spec/example.json.txt)
INI Example
[>>>
title = My Example Feed
home_page_url = https://example.org/
feed_url = https://example.org/feed.txt
</>
id = 2
url = https://example.org/second-item
---
This is a second item.
</>
id = 1
url = https://example.org/initial-post
---
Hello, world!
<<<]
or
[>>>
title: My Example Feed
home_page_url: https://example.org/
feed_url: https://example.org/feed.txt
</>
id: 2
url: https://example.org/second-item
---
This is a second item.
</>
id: 1
url: https://example.org/initial-post
---
Hello, world!
<<<]
(Source: feeds/spec/example.ini.txt)
Note: Use [>>> and <<<] to begin and end your Feed.TXT.
Use </> for first or next item
and --- for meta blocks inside items.
